
O que aconteceria no mundo se fosse possível conquistar em dez dias os avanços tecnológicos que normalmente demorariam dez anos para serem alcançados? Essa pergunta já começa a ser respondida por algumas empresas de tecnologia que vêm avançando de forma significativa no uso de inteligência artificial pós-pandemia. Este movimento deve-se, em grande parte, à evolução no uso de dados sintéticos.
A multinacional de IA Nvidia publicou em julho uma demonstração da sua promessa de obter resultados de ‘dez anos de treinamento virtual em apenas dez dias de tempo real’. Utilizando um de seus simuladores GPU, capazes de processar gigantes quantidades de dados e que são usados hoje pela NASA, e novas técnicas de visão computacional e de construção de redes neurais, a empresa criou um modelo para treinar avatares lutadores.

Agente da NVIDIA sendo treinado a partir do uso de dados sintéticos. Fonte: Youtube
Esses agentes não apenas adquiriram habilidades motoras em 0,27% do tempo que um simulador virtual com uso de dados puramente reais entregaria, como também demonstraram maior precisão de movimentos, de deslocamento e de controlo para sair de várias situações aleatórias às quais foram expostos.
A grande sacada aqui está na forma como os sistemas foram programados para treinar os agentes: dados sintéticos foram utilizados para criar um conjunto de movimentos não estruturado, com os agentes a receber diretamente exemplos de movimentos que a empresa gostaria que executassem. O jeito tradicional seria projetar um conjunto de tarefas específicas para os agentes executarem e construírem um repertório, passo a passo, à medida em que interagem no ambiente virtual (como na prática convencional de animação de personagens).
A Nvidia ainda sobrepôs o conjunto de movimento não estruturado construído a partir de dados sintéticos com um segundo, que simula movimentos com dados reais. Ou seja, o que vemos na tela é um movimento que o olho humano reconhece como verdadeiro. É possível conhecer o framework do que a NVIDIA fez neste paper. Este é um dos exemplos interessantes do que hoje investigadores da inteligência artificial veem como nova fronteira de evolução. Depender de dados reais faria os agentes virtuais demorarem até dez anos para ser capazes de lutar em um nível convincente para nosso olho humano. Mas não é só o custo do tempo o problema, é também o de oportunidade.
Por que olhar para os dados sintéticos
Depender da recolha de dados reais ficou caro e demorado, perigoso (riscos cibernéticos, de segurança e privacidade) para muitos negócios. Numa pesquisa recente com 100 executivos de diversos setores, sendo quase um terço deles pertencentes a empresas com mais de 1 mil funcionários, 82% reconhecem que sua empresa está em risco quando recolha dados do ‘mundo real’. Em termos de oportunidades de inovação, a dependência de dados reais para criar serviços e produtos com inteligência artificial deu maior poder de barganha a um rol pequeno de empresas de tecnologia que alimentaram suas bases por anos com informações de utilizadores sem serem incomodadas. Partilhar dados pessoais para empresas em troca dos seus serviços também não é a vontade de 51% dos consumidores, segundo uma pesquisa da Privitar.
Dados sintéticos vs dados reais
Dados sintéticos são amostras geradas artificialmente por computadores: ou seja, não foram obtidos através da observação direta do mundo real e recolha de informações. Aproveitam-se recursos de computação para criá-los, sem depender de trabalho humano para recolhê-los, limpá-los ou realizar a curadoria do que usar. Na prática, isso significa que “é possível construir modelos de machine learning que queremos, quando queremos”, usando a definição de Lina Avancini Colucci, da Infinity IA. “Em outras palavras: os dados sintéticos permitem construir um pipeline que é orientado por metas versus orientado por disponibilidade de dados”, escreveu Avancini.
Alexander Linden, VP Analyst do Gartner, analisou que, embora os dados reais sejam quase sempre a melhor fonte de insights, os sintéticos podem ajudar a criar ou treinar modelos de IA mais precisos e versáteis. Também podem servir de complemento: criando um conjunto que aprimore ou mitigue pontos fracos dos dados reais. Linden exemplifica: dados reais são casuais, contêm vieses ou refletem apenas eventos possíveis no mundo real, deixando de fora condições não vistas e limitando resultados e inovações. “Quando dados sintéticos estão disponíveis em abundância, há a capacidade de selecionar (e criar) dados para necessidades específicas, em vez de ficar limitado ao que está disponível e de código aberto em plataformas”. Em países africanos, por exemplo, onde uma parte significativa da população não tem acesso à internet, é um desafio recolhar dados reais para personalizar ofertas virtuais ou até criar sistemas de detecção de fraude no e-commerce.
O MIT defende que “dados artificiais podem ser usados para treinar IAs em áreas onde os dados reais são escassos ou muito sensíveis para uso, como no caso de registos médicos ou dados financeiros pessoais”. E lembra que, muito embora, a ideia de dados sintéticos não seja nova (carros sem motorista foram treinados em ruas virtuais), no ano passado a tecnologia espalhou-se, com uma série de startups e universidades oferecendo dados sintéticos ou ferramentas de códigos abertos para criação deles. Até 2024, aliás, 60% dos dados usados para o desenvolvimento de IA e análises de projetos serão gerados sinteticamente, prevê o Gartner. Se os dados são o novo petróleo, usar o sintético é como se estivéssemos criando o petróleo. Mas a um custo muito menor.
Os dilemas e perigos
Mas não é só de otimismo que se vive e, como tudo na vida, há desafios, barreiras e cuidados a serem levados em conta. Os dados sintéticos apresentam os seus próprios problemas, sendo um deles a mudança de domínio que surge porque os dados sintéticos não são reais. A startup Synthesis IA vê isso como um desafio: é preciso treinar um modelo num domínio (dados sintéticos) e aplicá-lo num domínio diferente (dados reais), o que leva a todo um campo de IA chamado de adaptação de domínio. Além disso, há o próprio questionamento sobre se, de facto, dados sintéticos são realmente capazes de substituir dados reais. Um estudo publicado por investigadores da Carnegie Mellon descreveu 10 desafios para o que defendem ser um grande problema atual: a lacuna de realidade dos dados sintéticos.
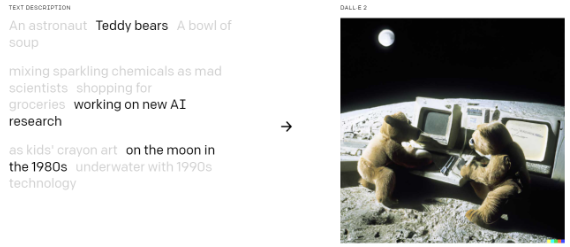
E há, claro, questionamentos éticos que persistem. Empresas criam um carro autónomo a partir de informações sintéticas de trânsito, movimentação, cidades e comportamento humano. Se um acidente ocorre, a culpa é de quem? Se foi a própria máquina quem treinou a máquina, de quem é a responsabilidade? O próprio DALL-E, um dos exemplos mais bem-sucedidos e conhecidos hoje sobre uso de IA para gerar imagens automaticamente a partir de descrições de texto, reconhece que precisa analisar ainda como o seu produto, criado partir de 12 mil milhões de parâmetros treinados, se relaciona a questões sociais e econômicas. Bem como o potencial que o seu produto tem de gerar imagens a partir de certos vieses. De todo modo, o que o DALL-E está criando é fascinante em termos de geração de imagens a partir do zero, de novas combinações possíveis e de transformação do que entendemos hoje por linguagem, imagem e percepção visual.
Exemplo de imagem gerada automaticamente pelo DALL-E a partir de indicações escritas. Fonte: https://openai.com/blog/dall-e/
O potencial dos dados sintéticos
Embora a sua evolução caminhe com riscos, os dados sintéticos têm o potencial de transformar a economia, a forma como tomadores de decisão prevê comportamentos de mercado e até de moldar o que podemos falar em nova geopolítica dos dados. Ao democratizar o acesso a dados, mesmo que sintéticos, empresas menores poderão começar a concorrer com alguma chance com players que, talvez antes, nunca teriam a chance de desafiar. Utilizadores também não precisariam trocar suas informações pessoais pelo uso de um serviço.
O próprio Facebook (atual Meta), depois de tantas ações e processos contra a sua recolha e uso irregular de dados pessoais dos utilizadores, percebeu que tem uma lacuna a ser preenchida. Segundo o VentureBeat, a Meta adquiriu sem muito alarde um dos primeiros serviços dedicados a dados sintéticos, o AI.Reverie. “Esta aquisição destaca que mesmo uma empresa como o Facebook, conhecida pela sua vasta base de dados, ainda tem um gap na sua capacidade de recolher o que é necessário para treinar a IA”. Quem dominar com segurança o dado sintético, vai dominar uma parte importante do futuro: fazendo o próprio metaverso, o próprio filme, um comercio eletrónico muito mais personalizado, criando novos cenários de estudos, cidades virtuais e previsões para os negócios. E como os agentes da Nvidia já demonstraram: nós não temos dez anos para esperar que o modelo perfeito esteja pronto.
Este artigo foi produzido por Guga Stocco, colunista da MIT Technology Review Brasil.